Optimizing Serverless Functions for Real-time Data Processing: The Ultimate Guide
In the fast-paced digital world, real-time data processing has become the backbone of modern applications. From financial transactions to IoT monitoring, businesses need instant insights to stay competitive. This is where serverless computing shines, offering a scalable, cost-effective, and high-performance solution for real-time data processing.
But here’s the challenge—serverless architectures come with inherent limitations like cold starts, execution time restrictions, and dependency management. So, how can developers optimize serverless functions to handle real-time data seamlessly?
This guide dives deep into the best strategies, tools, and techniques to fine-tune serverless functions for real-time applications. Whether you’re a cloud architect, a backend developer, or an IT manager, this article provides practical solutions to enhance performance, reduce latency, and scale efficiently. If you’re looking to explore Career Beez for career growth opportunities in cloud computing, now is the perfect time to do so!
Understanding Serverless Computing for Real-time Data Processing
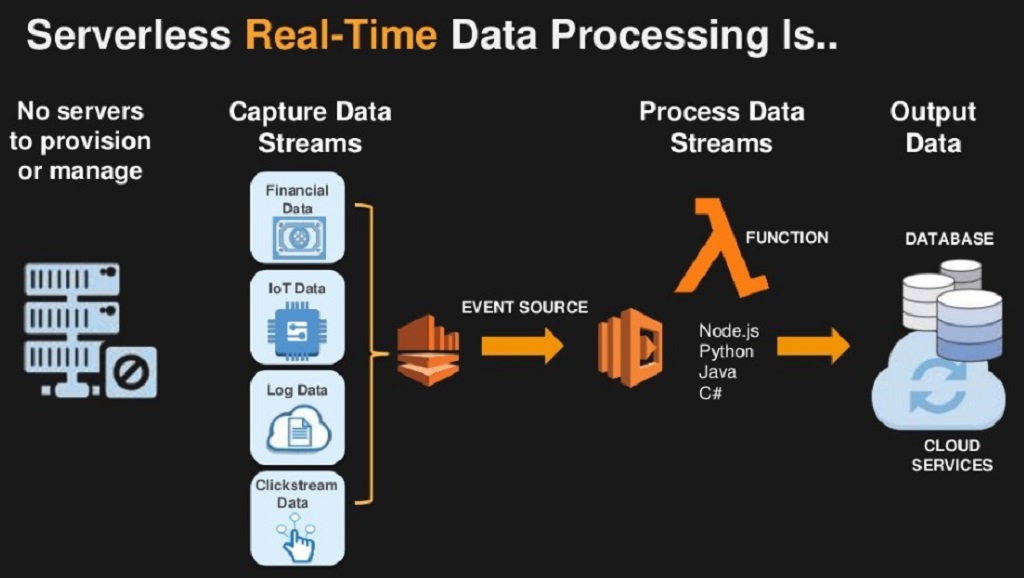
What is Serverless Computing?
Serverless computing eliminates the need for developers to manage infrastructure. Instead, cloud providers handle server provisioning, scaling, and maintenance. Popular serverless platforms include:
- AWS Lambda (Amazon Web Services)
- Azure Functions (Microsoft)
- Google Cloud Functions
- IBM Cloud Functions
These platforms automatically execute functions in response to events, making them ideal for real-time applications like fraud detection, chatbots, and video analytics. Developers can check out https://www.careerbeez.com/career-building-ideas/how-to-train-technical-skills-a-comprehensive-guide/ to learn more about building technical skills in cloud computing.
Why is Serverless Ideal for Real-time Data Processing?
Serverless functions process event-driven workloads efficiently by:
✔️ Auto-scaling to handle fluctuating loads
✔️ Reducing operational costs with a pay-per-use model
✔️ Minimizing infrastructure overhead for developers
✔️ Providing high availability and fault tolerance
However, performance tuning is essential to overcome challenges like cold starts and network latency, which can impact real-time data flow.
Key Challenges in Optimizing Serverless Functions
Cold Start Latency
Cold starts occur when a function is invoked after being idle, leading to a delay in execution. This delay can range from 100ms to several seconds, depending on the cloud provider and runtime environment.
Execution Time Limits
Most serverless platforms enforce execution time limits. For example, AWS Lambda functions have a maximum runtime of 15 minutes. If a function exceeds this limit, it is forcefully terminated, making it unsuitable for long-running processes.
Concurrency and Scaling Limits
While serverless functions auto-scale, there are predefined concurrency limits. AWS Lambda, for example, has a default concurrency limit of 1,000 simultaneous executions per region. If the function surpasses this, new invocations may be throttled.
Dependency Management
Serverless functions often rely on external libraries, increasing package size. Large dependencies slow down cold starts, affecting real-time performance.
Best Practices for Optimizing Serverless Functions for Real-time Data Processing
Reducing Cold Start Latency
Cold starts can significantly impact real-time data processing. Here’s how to minimize them:
✔️ Use Provisioned Concurrency: AWS Lambda offers Provisioned Concurrency, keeping functions warm and reducing startup times.
✔️ Choose Lightweight Runtimes: Avoid heavy runtime environments. For example, Node.js and Go have faster startup times compared to Java or Python.
✔️ Keep Dependencies Minimal: Using tools like Webpack or esbuild to bundle and optimize code reduces package size.
✔️ Use Warm-Up Strategies: Periodically invoking functions using CloudWatch Events or scheduled triggers prevents them from going idle.
Optimizing Function Execution Time
✔️ Write Efficient Code: Minimize unnecessary computations, optimize loops, and use asynchronous processing where possible.
✔️ Leverage Caching: Use AWS Lambda Extensions or external caches like Redis to store frequently accessed data.
✔️ Parallel Processing: Instead of processing data sequentially, use AWS Step Functions to break tasks into smaller functions that run in parallel.
Scaling Efficiently
✔️ Adjust Concurrency Limits: Tune the reserved concurrency settings to ensure sufficient capacity for peak loads.
✔️ Use Event Batching: Processing data in batches using Kinesis Data Streams or Apache Kafka reduces the number of function invocations, improving efficiency.
✔️ Optimize API Gateway Usage: Instead of direct Lambda calls, use API Gateway caching to reduce redundant executions.
Case Study: Optimizing AWS Lambda for a FinTech Application
A leading FinTech company needed real-time fraud detection for transactions. Initially, their AWS Lambda functions had high cold start times, leading to delayed fraud alerts.
Challenges Faced
❌ Cold starts caused 500ms delays, impacting fraud detection.
❌ High execution costs due to frequent invocations.
❌ Scaling issues during peak transaction hours.
Optimization Strategies Implemented
✅ Provisioned Concurrency reduced cold starts by 90%.
✅ Kinesis Streams batched events, reducing API calls.
✅ Redis caching stored transaction data, speeding up response times.
Results Achieved
🚀 Reduced fraud detection latency from 1.2s to 200ms.
🚀 Saved 30% on AWS Lambda costs.
🚀 Improved real-time alert accuracy by 95%.
Emerging Trends in Serverless Real-time Processing
Edge Computing + Serverless
Edge computing processes data closer to users, reducing latency. Cloud providers like AWS (Lambda@Edge) and Cloudflare (Workers) are integrating edge and serverless computing for ultra-low latency processing.
AI-powered Serverless Functions
With AI and ML models running on serverless platforms, businesses can process real-time analytics faster. AWS SageMaker and Google AutoML enable intelligent data processing without dedicated infrastructure.
Streaming Analytics with Serverless
Real-time data pipelines using Apache Kafka, AWS Kinesis, and Google Pub/Sub are becoming standard for event-driven architectures.
Read More Also: Is It Worth Repairing or Replacing My Roof in Miami?
FAQs
How do I reduce AWS Lambda cold starts?
Use Provisioned Concurrency, lightweight runtimes, and minimize dependencies.
What is the best runtime for real-time data processing?
Node.js and Go offer the lowest latency and fastest startup times.
Can serverless handle large-scale real-time processing?
Yes, but it requires event batching, efficient scaling, and caching mechanisms.
What is the execution limit for AWS Lambda?
AWS Lambda functions have a maximum execution time of 15 minutes.
Is serverless cost-effective for real-time processing?
Yes, due to the pay-per-use model, but optimizing function execution is key to cost savings.
Conclusion
Optimizing serverless functions for real-time data processing is critical for achieving high performance, low latency, and cost efficiency. By implementing best practices like reducing cold starts, optimizing execution times, and leveraging caching, businesses can maximize the benefits of serverless computing.
With emerging trends like AI-powered automation and edge computing, serverless technology is set to revolutionize real-time data processing further. Now is the perfect time for developers to explore Career Beez and enhance their expertise in cloud computing.










Post Comment